
AI Monitoring in Healthcare: Why Voice Intelligence Matters More Than Ever
Pushing the Limits of Deepfake Voice Detection: How Modulate’s Latest Model Raises the Bar
October 30, 2025

Sawyer S.
(HE/HIM/HIS)

.webp)
If you’ve picked up a newspaper or scrolled through social media lately, you’ve probably seen stories about deepfake voices: AI-generated audio that sounds uncannily like real people. From cloned celebrity voices to scammers pretending to be the CFO of your company or even someone pretending to be a loved one claiming to need a lot of money now, this technology has gotten good. Sometimes too good - at least, for humans to tell the difference.
Thankfully, at Modulate, we’re experts on voice - including those subtle signs that show a voice is synthetic. In fact, our synthetic voice detection is the most accurate on the market…and it’s only the beginning of the insights we provide. We’re excited to share more about how this model was built, and the deeper meaning of the difference between “synthetic” voices and true “deepfakes.”
Why Detecting Fake Voices Is Harder Than It Sounds
Human voices are naturally imperfect. When we speak, our pitch, cadence, and tone shift in tiny, irregular ways. We pause, emphasize words differently, or let our emotions shape our pitch. AI-generated voices often miss these subtleties. They can sound too smooth or consistent, almost robotic.
In older deepfakes, those flaws were obvious to most of us. But today’s advanced audio generation tools hide them so well that even experts struggle to tell real from fake. Scammers use these synthetic voices in contexts where you might not be on the lookout for malicious intent, such as in a phone call with someone claiming to be a bank representative or someone from your senator’s community outreach staff. That’s where deepfake detection models like ours come in.
How Our Model Works
To spot what human ears can’t, our new model draws on three key strengths:
- A world-class foundation
In our years of operation, Modulate has had the opportunity to analyze a unique dataset of voice content with varying levels of noise, audio quality, emotion, languages and accents, and much more. We’ve processed hundreds of millions of hours of such content to help us keep improving. This expertise gives us a much deeper understanding of how real human speech should look and sound. - Attention to every detail
The “giveaway” for synthetic voices can vary. Sometimes it’s an issue with the vocal tones, visible in tiny snippets of speech, but other times it’s more about rhythm or pronunciation, which require a model to review much longer segments in order to recognize. By utilizing a learned layer weighting mechanism, our model is able to leverage both types of insight and catch indications however they emerge. - Training for the real world
We fine-tuned our model with over half a million diverse audio samples from different speakers, environments, and synthetic voice generation tools, pulling from our proprietary dataset to get the best representation of voices across various contexts and audio qualities. We also used advanced augmentation techniques that take advantage of our years of experience and deeper datasets, like adding variable background noise to ensure the model knows what kinds of audio artifacts come from real-world recordings and can more clearly contrast those with artificial glitches.
The Results: Smarter, Faster, More Reliable
When compared to other proprietary speech deepfake detection models, Modulate’s system sets itself apart in the following ways:
- Performance: In the premier metric for accuracy, known as an F1 score, Modulate’s model outperforms every other model with published results, measured against 12 industry standard datasets for synthetic voice detection.
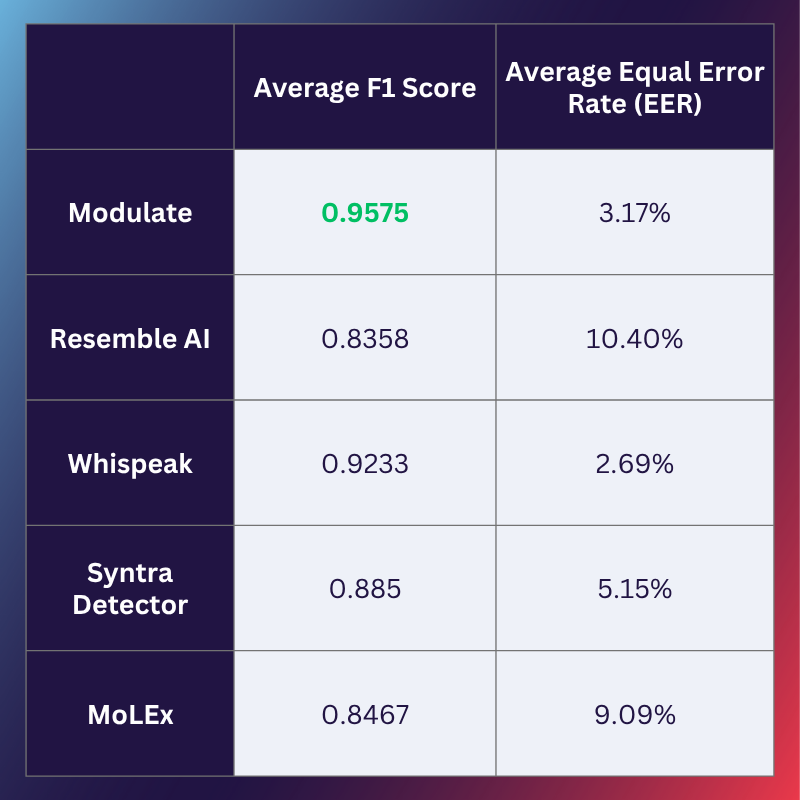
- Efficiency: It only takes less than 5 seconds of audio for our model to make a confident prediction, allowing our model to identify synthetic callers faster to help customers reroute, deprioritize, or otherwise appropriately handle synthetic vs human callers. Oh, and it does this analysis fully in the background, without adding any friction to the user experience.
- Cost: While some organizations focus on massive models with slower inference speed, Modulate’s models are lightning-quick and thus also much more cost-effective when monitoring many conversations at scale.
- Consistency: Our model has better generalization to unseen deepfake generation techniques and is more robust against background noise, phone call conditions, and other real-world challenges.
Our model not only detects fake voices more accurately, it does it faster and more reliably in real-world conditions.
Yet That’s Only Half Of What We Can Do
What we’ve described so far is our synthetic voice detection model, which already delivers world-class results. But unlike any other technology provider, we’re not stopping there. At Modulate, we know that not every synthetic voice is actually intended for fraud, so we go a step further to determine whether a synthetic voice is actually a deepfake.
For us, the difference is one of intent. A synthetic voice might be used by an individual who cannot speak, or is suffering from voice dysphoria, in a fully authentic way. Our partners, including customer support centers, banks and insurance carriers, and delivery platforms, do not want to hurt the experience of these well-intentioned users simply because they need or choose to use a synthetic voice.
So we augment our synthetic voice detection with conversational analysis - a skill Modulate has honed over years of listening to gaming voice chat to tell the difference between genuine harassment and friendly chats, and more recently has deployed to help Fortune 500 companies catch 5x more attempted fraud with industry-leading consistency and accuracy.
As one example, if a synthetic voice opens the conversation by emphasizing that their need is extremely urgent, that’s a bit of a warning sign. If they start making assertions like “this was already cleared by your CEO, don’t you dare waste my time”, that’s an ever bigger red flag. Even smaller conversational elements - like slow response times or trouble with turn-taking - can be used by our models to enrich our understanding of whether we’re speaking to an honest human through a synthetic voice, a fully automated agent (with good or ill intent), or a fraudster attempting to mask their voice or manipulate an agent through a more sympathetic, impressive, or simply un-suspicious voice.
Put simply, the world-class accuracy of our synthetic model is where our solution starts, and it only gets better from there as we really dig into the questions that matter to you - not just what kind of voice you’re hearing, but what the intent is behind it.
Why Synthetic Voice and Deepfake Detection Matters
Voice fraud isn’t science fiction anymore; even government leaders and executives are being targeted. Criminals can already clone voices with just a few minutes of audio, posing a growing risk for banks, insurers, retailers, delivery platforms, and even ordinary consumers answering the phone.
Modulate’s conversational intelligence platform, powered by these industry-leading models, offers a robust, reliable, and battle-tested defense against this threat. We’re already helping organizations:
- Catch fraud before money or sensitive data changes hands.
- Protect agents and employees from abusive fake calls.
- Build customer trust in the safety of voice-based services.
And much more. Reach out here to try it for yourself! See how your ears stack up to our detection model capabilities in our Deepfake Detection quiz.
The AI world is nothing if not fast-moving, so at Modulate, we’re never resting on our laurels. We’re constantly monitoring new breakthroughs and continuously iterating on our models to stay ahead of the curve and make sure you stay protected. Through the millions of hours of conversations we monitor each month, our dedicated research, and our models’ abilities to surface new behaviors they’re unsure about, we’ve built a proven process to pre-empt the majority of threats and close the gap at lightning speed when a new innovation catches the world by surprise.
Deepfake voices are getting better every day. But so are we. And with tools like this, we’re staying one step ahead to keep conversations safe.


